KI funktioniert bei der Diagnose und Behandlung von Glaukom genauso gut oder sogar besser als menschliche Augenärzte. Es stimmt auch mit Augenärzten bei der Behandlung von Netzhauterkrankungen überein.
Auswertung der Antworten eines großen Sprachmodells auf Fragen und Fälle zum Thema Glaukom und Netzhautmanagement Wichtige Punkte Fragen Kann ein LLM-Chatbot (Large Language Model) im Vergleich zu Augenärzten, die in der Behandlung von Glaukom und Netzhauterkrankungen geschult sind, genaue und vollständige Antworten liefern? Ergebnisse In dieser Querschnittsstudie, bei der die Antworten anhand einer Likert-Skala bewertet wurden, zeigte der LLM-Chatbot eine vergleichende Kompetenz, die den Glaukom- und Netzhaut-Subspezialisten bei der Beantwortung ophthalmologischer Fragen und dem Patientenfallmanagement weitgehend ebenbürtig, wenn nicht sogar überlegen war. Bedeutung Die Ergebnisse unterstreichen den potenziellen Nutzen von LLMs als wertvolle diagnostische Hilfsmittel in der Augenheilkunde, insbesondere in chirurgischen und hochspezialisierten Teilgebieten des Glaukoms und der Netzhaut. |
Bedeutung
Large Language Models (LLM) revolutionieren die medizinische Diagnose und Behandlung und bieten eine beispiellose Genauigkeit und Benutzerfreundlichkeit, die herkömmliche Suchmaschinen übertrifft. Seine Integration in Gesundheitsprogramme wird für Augenärzte als Ergänzung zur Praxis der evidenzbasierten Medizin von wesentlicher Bedeutung sein. Daher kann die Genauigkeit der Diagnose- und Behandlungsreaktionen, die von LLM im Vergleich zu ausgebildeten Augenärzten generiert werden, dazu beitragen, ihre Genauigkeit zu bewerten und ihren potenziellen Nutzen in ophthalmologischen Subspezialitäten zu validieren.
Ziel
Vergleich der diagnostischen Genauigkeit und Breite der Antworten eines LLM-Chatbots mit denen von Glaukom- und Netzhautspezialisten, die in ophthalmologischen Fragen und dem Management realer Patientenfälle geschult sind.
Design, Umgebung und Teilnehmer
Für diese vergleichende Querschnittsstudie wurden 15 Teilnehmer im Alter von 31 bis 67 Jahren, darunter 12 behandelnde Ärzte und 3 leitende Auszubildende, aus Augenkliniken rekrutiert, die der Abteilung für Augenheilkunde an der Icahn School of Medicine am Mount Sinai, New York, New York, angeschlossen sind. Die Fragen zu Glaukom und Netzhaut (10 von jedem Typ) wurden zufällig aus den am häufigsten gestellten Fragen der American Academy of Ophthalmology ausgewählt.
Nicht identifizierte Glaukom- und Netzhautfälle (10 von jedem Typ) wurden zufällig aus Augenheilkundepatienten ausgewählt, die in Kliniken der Icahn School of Medicine am Mount Sinai behandelt wurden. Als LLM wurde GPT-4 (Version vom 12. Mai 2023) verwendet. Die Daten wurden von Juni bis August 2023 erhoben.
Wichtigste Ergebnisse und Maßnahmen
Die Antworten wurden anhand einer Likert-Skala bewertet, um die medizinische Genauigkeit und Vollständigkeit zu ermitteln. Die statistische Analyse umfasste den Mann-Whitney-U-Test und den Kruskal-Wallis-Test, gefolgt von einem paarweisen Vergleich.
Ergebnisse
Die kombinierte durchschnittliche Bewertung der Fragefälle für die Genauigkeit betrug 506,2 für den LLM-Chatbot und 403,4 für Glaukomspezialisten (n = 831; Mann-Whitney U = 27976,5; P < 0,001), und die durchschnittliche Bewertung für die Vollständigkeit betrug 528,3 und 398,7. bzw. (n = 828; Mann-Whitney U = 25218,5; P < .001).
Die mittlere Genauigkeitsbewertung betrug 235,3 für den LLM-Chatbot und 216,1 für die Netzhautspezialisten (n = 440; Mann-Whitney U = 15.518,0; P = .17), und die mittlere Vollständigkeitsbewertung betrug 258,3 bzw. 208,7 (n = 439; Mann-Whitney U = 13123,5; P = .005).
Dunns Test ergab einen signifikanten Unterschied zwischen allen paarweisen Vergleichen außer zwischen dem Spezialisten und dem Auszubildenden bei der Bewertung der Chatbot-Integrität. Insgesamt zeigten paarweise Vergleiche, dass sowohl Lernende als auch Spezialisten die Genauigkeit und Vollständigkeit des Chatbots positiver bewerteten als ihre Fachkollegen, wobei Spezialisten einen signifikanten Unterschied in der Genauigkeit und Vollständigkeit des Chatbots (z = 3,23; P = 0,007) und Integrität (z = .007) feststellten 5,86; p < .001).
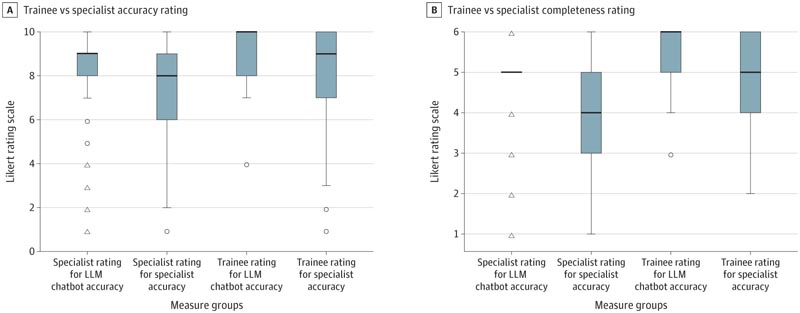
Abbildung : In den dargestellten Boxplots gibt die Box den IQR zwischen dem ersten und dritten Quartil an; die Mittellinie gibt den Median des Datensatzes an; Whiskers zeigen das 1,5-fache des IQR an; Kreise zeigen leichte Ausreißer an (Werte zwischen dem 1,5- und 3-fachen des IQR); und Dreiecke weisen auf extreme Ausreißer hin (mehr als das Dreifache des IQR).
Schlussfolgerungen und Relevanz
Diese Studie unterstreicht die vergleichende Kompetenz von LLM-Chatbots in Bezug auf diagnostische Genauigkeit und Vollständigkeit im Vergleich zu ausgebildeten Augenärzten in verschiedenen klinischen Szenarien.
Der LLM-Chatbot übertraf Glaukomspezialisten und Netzhautspezialisten hinsichtlich der Diagnose- und Behandlungsgenauigkeit und untermauerte seine Rolle als vielversprechendes diagnostisches Hilfsmittel in der Augenheilkunde.
Kommentare
Die neue Studie testete die KI mit einem Gremium menschlicher Ärzte, indem sie 20 Patientenfälle auswertete.
Laut einer neuen Studie kann künstliche Intelligenz bei der Diagnose und Behandlung von Glaukom mit menschlichen Augenärzten mithalten und diese sogar übertreffen.
Das GPT-4-System von OpenAI schnitt bei der Untersuchung von 20 verschiedenen Patienten auf Glaukom und Netzhauterkrankungen genauso gut oder besser ab als Augenärzte, berichten die Forscher in der Fachzeitschrift JAMA Ophthalmology .
„Die KI zeichnete sich besonders durch ihre Kompetenz im Fallmanagement von Glaukom- und Netzhautpatienten aus, da sie die Genauigkeit und Vollständigkeit der Diagnosen und Behandlungsvorschläge von menschlichen Ärzten in einem klinischen Notizformat widerspiegelte“, sagte der Hauptautor der Studie, Dr . Louis Pasquale, Vizepräsident für Augenheilkundeforschung am Eye and Ear Infirmary am Mount Sinai in New York.
Die Ergebnisse legen nahe, dass KI für Augenärzte eine wichtige unterstützende Rolle bei der Behandlung von Glaukompatienten spielen könnte.
„So wie die KI-App Grammarly uns beibringen kann, bessere Autoren zu werden, kann GPT-4 uns wertvolle Hinweise geben, wie wir bessere Ärzte werden können, insbesondere im Hinblick darauf, wie wir Ergebnisse von Patientenuntersuchungen dokumentieren“, sagte Pasquale in einer Erklärung . Pressemitteilung zum Thema Pflege.
Ein Glaukom ist bekanntermaßen schwer zu diagnostizieren. Nach Angaben der American Academy of Ophthalmology (AAO) wissen etwa die Hälfte der 3 Millionen Amerikaner mit Glaukom nicht, dass sie daran leiden.
Ein Glaukom tritt auf, wenn sich im Auge ein Flüssigkeitsdruck aufbaut, der den Sehnerv schädigt und blinde Flecken im Sehvermögen einer Person verursacht, so die AAO.
Für diese Studie verwendeten die Forscher einen Kernsatz von 20 Fragen zu Glaukom und Netzhauterkrankungen, um das KI-Programm mit 12 behandelnden Augenärzten und drei leitenden Auszubildenden zu testen.
Anschließend wurden die Antworten statistisch analysiert und hinsichtlich Genauigkeit und Gründlichkeit bewertet.
Die Ergebnisse zeigen, dass die künstliche Intelligenz bei der Glaukomdiagnose und -behandlung besser abschneidet als Augenärzte. Bei Netzhauterkrankungen kam die KI in der Genauigkeit mit dem Menschen mit, übertraf ihn jedoch in der Vollständigkeit.
Die Forscher stellten fest, dass fortschrittliche KI-Tools wie GPT-4 auf große Daten-, Text- und Bildmengen trainiert werden.
Der leitende Forscher Dr. Andy Huang, Assistenzarzt für Augenheilkunde am Mount Sinai Eye and Ear Infirmary in New York, sagte, die Ergebnisse zeigten, dass KI bei der Behandlung von Augenkrankheiten helfen kann.
„Es könnte als zuverlässiger Assistent für Augenärzte dienen, indem es ihnen diagnostische Unterstützung bietet und ihnen möglicherweise die Arbeit erleichtert, insbesondere bei komplexen Fällen oder Bereichen mit hohem Patientenaufkommen“, sagte Huang.
„Für Patienten könnte die Integration von KI in die konventionelle Augenheilpraxis zu einem schnelleren Zugang zu Expertenrat und einer fundierteren Entscheidungsfindung zur Steuerung ihrer Behandlung führen“, fügte Huang hinzu.
Letzte Nachricht In dieser Studie erzielte ein LLM-Chatbot eine vergleichbare und umfassende diagnostische Genauigkeit bei Glaukom und Netzhaut im Vergleich zu ausgebildeten Augenärzten sowohl bei klinischen Fragen als auch bei klinischen Fällen. Diese Ergebnisse stützen die Möglichkeit, dass Werkzeuge der künstlichen Intelligenz sowohl als diagnostische als auch therapeutische Hilfsmittel eine entscheidende Rolle spielen könnten. |
QUELLE: New York Eye and Ear Infirmary of Mount Sinai, Pressemitteilung, 22. Februar 2024