L’intelligenza artificiale funziona altrettanto bene o meglio degli oftalmologi umani nella diagnosi e nel trattamento del glaucoma. Concorda inoltre con gli oftalmologi nella gestione delle malattie della retina.
Valutazione delle risposte di un ampio modello linguistico a domande e casi sul glaucoma e sulla gestione della retina Punti chiave Può un chatbot Large Language Model (LLM) fornire risposte accurate e complete rispetto agli oftalmologi formati nella gestione del glaucoma e delle malattie della retina? Risultati In questo studio trasversale, con risposte valutate utilizzando una scala Likert, il chatbot LLM ha dimostrato competenza comparativa, in gran parte eguagliando, se non superando, i subspecialisti del glaucoma e della retina nell’affrontare domande oftalmologiche e nella gestione dei casi dei pazienti. Senso I risultati sottolineano la potenziale utilità degli LLM come preziosi complementi diagnostici in oftalmologia, in particolare nelle sottospecialità chirurgiche e altamente specializzate del glaucoma e della retina. |
Importanza
I Large Language Models (LLM) stanno rivoluzionando la diagnosi e il trattamento medico, offrendo una precisione e una facilità senza precedenti che superano i motori di ricerca convenzionali. La sua integrazione nei programmi sanitari sarà essenziale per gli oftalmologi come complemento alla pratica della medicina basata sull’evidenza. Pertanto, l’accuratezza delle risposte diagnostiche e terapeutiche generate da LLM rispetto agli oftalmologi formati può aiutare a valutarne l’accuratezza e convalidare la sua potenziale utilità nelle sottospecialità oftalmiche.
Scopo
Confrontare l’accuratezza diagnostica e l’ampiezza delle risposte di un chatbot LLM con quelle di specialisti del glaucoma e della retina formati in domande oftalmologiche e nella gestione dei casi reali dei pazienti.
Design, ambiente e partecipanti
Questo studio trasversale comparativo ha reclutato 15 partecipanti di età compresa tra 31 e 67 anni, inclusi 12 medici curanti e 3 tirocinanti senior, da cliniche oftalmiche affiliate al Dipartimento di Oftalmologia presso la Icahn School of Medicine a Mount Sinai, New York, New York. Le domande sul glaucoma e sulla retina (10 per ciascun tipo) sono state selezionate casualmente tra le domande più frequenti dell’American Academy of Ophthalmology.
Casi di glaucoma e retina non identificati (10 per ciascun tipo) sono stati selezionati casualmente tra pazienti oftalmologici visitati presso la Icahn School of Medicine presso le cliniche affiliate al Monte Sinai. Il LLM utilizzato era GPT-4 (versione datata 12 maggio 2023). I dati sono stati raccolti da giugno ad agosto 2023.
Principali risultati e misure
Le risposte sono state valutate utilizzando una scala Likert per determinare l’accuratezza e la completezza medica. L’analisi statistica ha coinvolto il test U di Mann-Whitney e il test Kruskal-Wallis, seguiti dal confronto a coppie.
Risultati
La valutazione media combinata dei casi di domande per l’accuratezza era 506,2 per il chatbot LLM e 403,4 per gli specialisti del glaucoma (n = 831; Mann-Whitney U = 27976,5; P <0,001), e la valutazione media per la completezza era 528,3 e 398,7. rispettivamente (n = 828; Mann-Whitney U = 25218,5; P <0,001).
La valutazione media di accuratezza era 235,3 per il chatbot LLM e 216,1 per gli specialisti della retina (n = 440; Mann-Whitney U = 15.518,0; P = 0,17), e la valutazione media di completezza era 258,3 e 208,7, rispettivamente (n = 439; U di Mann-Whitney = 13123,5; P = 0,005).
Il test di Dunn ha rivelato una differenza significativa tra tutti i confronti a coppie, tranne tra lo specialista e il tirocinante, nella valutazione dell’integrità del chatbot. I confronti complessivi a coppie hanno mostrato che sia gli studenti che gli specialisti hanno valutato l’accuratezza e la completezza del chatbot in modo più favorevole rispetto alle loro controparti specializzate, con gli specialisti che hanno notato una differenza significativa nell’accuratezza e nella completezza del chatbot (z = 3,23; P = .007) e nell’integrità (z = 5,86; p < 0,001).
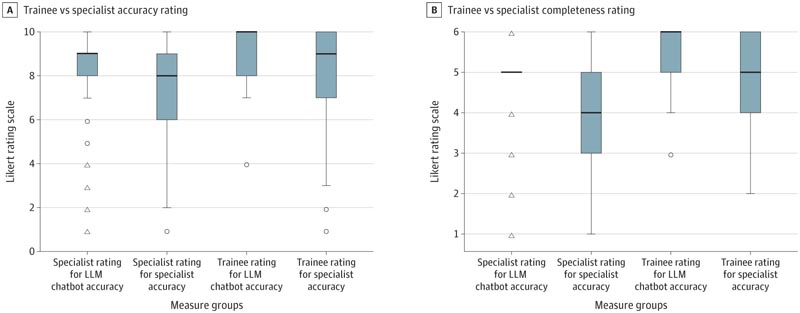
Figura : Nei boxplot presentati, il riquadro indica l’IQR tra il primo e il terzo quartile; la linea centrale indica la mediana del set di dati; i baffi indicano 1,5 volte l’IQR; i cerchi indicano lievi valori anomali (valori compresi tra 1,5 e 3 volte l’IQR); e i triangoli indicano valori anomali estremi (più di 3 volte l’IQR).
Conclusioni e rilevanza
Questo studio accentua la competenza comparativa dei chatbot LLM in termini di accuratezza e completezza diagnostica rispetto agli oftalmologi qualificati in vari scenari clinici.
Il chatbot LLM ha sovraperformato gli specialisti del glaucoma e ha abbinato gli specialisti della retina in termini di accuratezza diagnostica e terapeutica, supportando il suo ruolo di promettente complemento diagnostico in oftalmologia.
Commenti
Il nuovo studio ha testato l’intelligenza artificiale con un gruppo di medici umani valutando 20 casi di pazienti.
Secondo un nuovo studio, l’intelligenza artificiale può eguagliare e persino superare gli oftalmologi umani nella diagnosi e nel trattamento del glaucoma.
Il sistema GPT-4 di OpenAI ha funzionato altrettanto o meglio degli oftalmologi nella valutazione di 20 diversi pazienti per glaucoma e malattie della retina, riferiscono i ricercatori sulla rivista JAMA Ophthalmology .
"L’intelligenza artificiale è stata particolarmente sorprendente per la sua competenza nella gestione dei casi di pazienti affetti da glaucoma e retina, eguagliando l’accuratezza e la completezza delle diagnosi e dei suggerimenti terapeutici forniti da medici umani in formato nota clinica", ha affermato l’autore principale dello studio, il dott. Louis Pasquale, vicepresidente della ricerca oftalmologica presso l’Eye and Ear Infirmary del Mount Sinai a New York.
I risultati suggeriscono che l’intelligenza artificiale potrebbe svolgere un importante ruolo di supporto per gli oftalmologi nel tentativo di curare il glaucoma dei pazienti.
"Proprio come l’app Grammarly può insegnarci come essere scrittori migliori, GPT-4 può darci indicazioni preziose su come essere medici migliori, soprattutto in termini di come documentiamo i risultati degli esami dei pazienti", ha affermato Pasquale in una nota. . comunicato stampa infermieristico.
Il glaucoma è notoriamente difficile da diagnosticare. Secondo l’American Academy of Ophthalmology (AAO), circa la metà dei 3 milioni di americani affetti da glaucoma non sanno di averlo.
Il glaucoma si verifica quando la pressione del fluido si accumula all’interno dell’occhio, danneggiando il nervo ottico e creando punti ciechi nella visione di una persona, afferma l’AAO.
Per questo studio, i ricercatori hanno utilizzato una serie di 20 domande sul glaucoma e sulle malattie della retina per testare il programma di intelligenza artificiale con un gruppo di 12 oftalmologi partecipanti e tre tirocinanti senior.
Le risposte sono state poi analizzate statisticamente e valutate in termini di accuratezza e completezza.
I risultati mostrano che l’IA ha sovraperformato gli oftalmologi in risposta alla diagnosi e al trattamento del glaucoma. Per quanto riguarda le malattie della retina, l’intelligenza artificiale ha eguagliato gli esseri umani in termini di precisione, ma li ha superati in termini di completezza.
I ricercatori hanno notato che gli strumenti avanzati di intelligenza artificiale come GPT-4 vengono addestrati su grandi quantità di dati, testo e immagini.
Il ricercatore capo Dr. Andy Huang, oftalmologico residente presso il Mount Sinai Eye and Ear Infirmary di New York, ha affermato che i risultati mostrano che l’intelligenza artificiale può aiutare a curare le malattie degli occhi.
"Potrebbe fungere da assistente affidabile per gli oftalmologi fornendo loro supporto diagnostico e potenzialmente alleggerendo il loro carico di lavoro, soprattutto in casi complessi o aree con un elevato volume di pazienti", ha affermato Huang.
"Per i pazienti, l’integrazione dell’intelligenza artificiale nella pratica oftalmica convenzionale potrebbe comportare un accesso più rapido alla consulenza di esperti, insieme a un processo decisionale più informato per guidare il loro trattamento", ha aggiunto Huang.
Messaggio finale In questo studio, un chatbot LLM ha avuto un’accuratezza diagnostica comparativa e completa nel glaucoma e nella retina rispetto a oftalmologi qualificati sia nelle domande cliniche che nei casi clinici. Questi risultati supportano la possibilità che gli strumenti di intelligenza artificiale possano svolgere un ruolo fondamentale sia come strumenti diagnostici che terapeutici. |
FONTE: New York Eye and Ear Infirmary del Monte Sinai, comunicato stampa, 22 febbraio 2024