AI works as well or better than human ophthalmologists in diagnosing and treating glaucoma. It also agrees with ophthalmologists in the management of retinal diseases.
Evaluation of a large language model’s responses to questions and cases about glaucoma and retinal management Key points Can a large language model (LLM) chatbot provide accurate and complete answers compared to ophthalmologists trained in the management of glaucoma and retinal diseases? Findings In this cross-sectional study, with responses rated using a Likert scale, the LLM chatbot demonstrated comparative competence, largely matching, if not surpassing, glaucoma and retinal subspecialists in addressing ophthalmologic questions and patient case management. Meaning The findings underscore the potential utility of LLMs as valuable diagnostic adjuncts in ophthalmology, particularly in surgical and highly specialized subspecialties of glaucoma and retina. |
Importance
Large Language Models (LLM) are revolutionizing medical diagnosis and treatment, offering unprecedented accuracy and ease that surpass conventional search engines. Its integration into health care programs will be essential for ophthalmologists as a complement to the practice of evidence-based medicine. Therefore, the accuracy of diagnostic and treatment responses generated by LLM compared to trained ophthalmologists may help evaluate its accuracy and validate its potential utility in ophthalmic subspecialties.
Aim
To compare the diagnostic accuracy and breadth of responses from an LLM chatbot to those of glaucoma and retinal specialists trained in ophthalmological questions and real patient case management.
Design, environment and participants
This comparative cross-sectional study recruited 15 participants aged 31 to 67 years, including 12 attending physicians and 3 senior trainees, from ophthalmic clinics affiliated with the Department of Ophthalmology at the Icahn School of Medicine at Mount Sinai, New York, New York. The glaucoma and retina questions (10 of each type) were randomly selected from the American Academy of Ophthalmology’s most frequently asked questions.
Unidentified glaucoma and retinal cases (10 of each type) were randomly selected from ophthalmology patients seen at the Icahn School of Medicine at Mount Sinai-affiliated clinics. The LLM used was GPT-4 (version dated May 12, 2023). Data was collected from June to August 2023.
Main results and measures
Responses were evaluated using a Likert scale to determine medical accuracy and completeness. Statistical analysis involved the Mann-Whitney U test and the Kruskal-Wallis test, followed by pairwise comparison.
Results
The combined mean ranking of question cases for accuracy was 506.2 for the LLM chatbot and 403.4 for glaucoma specialists (n = 831; Mann-Whitney U = 27976.5; P < 0.001), and the mean rating for completeness was 528.3 and 398.7. respectively (n = 828; Mann-Whitney U = 25218.5; P < .001).
The mean accuracy rating was 235.3 for the LLM chatbot and 216.1 for the retinal specialists (n = 440; Mann-Whitney U = 15,518.0; P = .17), and the mean completeness rating was 258. .3 and 208.7, respectively (n = 439; Mann-Whitney U = 13123.5; P = .005).
Dunn’s test revealed a significant difference between all pairwise comparisons except between the specialist and the trainee in the rating of chatbot integrity. Overall pairwise comparisons showed that both learners and specialists rated the chatbot’s accuracy and completeness more favorably than their specialist counterparts, with specialists noting a significant difference in chatbot accuracy and completeness (z = 3.23; P = .007) and integrity (z = 5.86; p < .001).
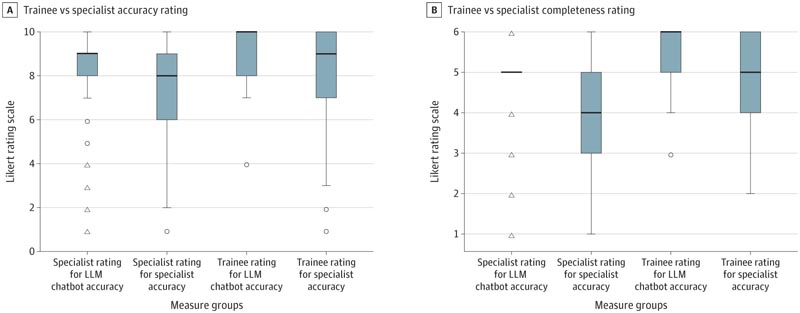
Figure : In the boxplots presented, the box indicates the IQR between the first and third quartiles; the center line indicates the median of the data set; whiskers indicate 1.5 times the IQR; circles indicate mild outliers (values between 1.5 and 3 times the IQR); and triangles indicate extreme outliers (more than 3 times the IQR).
Conclusions and relevance
This study accentuates the comparative proficiency of LLM chatbots in diagnostic accuracy and completeness compared to trained ophthalmologists in various clinical scenarios.
The LLM chatbot outperformed glaucoma specialists and matched retinal specialists in diagnostic and treatment accuracy, supporting its role as a promising diagnostic adjunct in ophthalmology.
Comments
The new study tested the AI with a panel of human doctors by evaluating 20 patient cases.
Artificial intelligence can match and even surpass human ophthalmologists in diagnosing and treating glaucoma, a new study finds.
OpenAI’s GPT-4 system performed as well or better than ophthalmologists in evaluating 20 different patients for glaucoma and retinal diseases, the researchers report in the journal JAMA Ophthalmology .
"The AI was particularly striking for its proficiency in case management of glaucoma and retina patients, matching the accuracy and completeness of diagnoses and treatment suggestions made by human doctors in a clinical note format," said the lead author of the study, Dr. Louis Pasquale, vice president of ophthalmology research at the Eye and Ear Infirmary at Mount Sinai in New York.
The results suggest that AI could play an important supporting role for ophthalmologists when trying to treat patients’ glaucoma.
"Just as the AI app Grammarly can teach us how to be better writers, GPT-4 can give us valuable guidance on how to be better doctors, especially in terms of how we document patient exam findings," Pasquale said in a statement. nursing press release.
Glaucoma is notoriously difficult to diagnose. About half of the 3 million Americans with glaucoma don’t know they have it, according to the American Academy of Ophthalmology (AAO).
Glaucoma occurs when fluid pressure builds up inside the eye, damaging the optic nerve and creating blind spots in a person’s vision, the AAO says.
For this study, the researchers used a core set of 20 questions about glaucoma and retinal diseases to test the AI program with a set of 12 attending ophthalmologists and three senior trainees.
The responses were then statistically analyzed and scored for accuracy and thoroughness.
The results show that AI outperformed ophthalmologists in response to glaucoma diagnosis and treatment. For retinal diseases, AI matched humans in accuracy but surpassed them in comprehensiveness.
The researchers noted that advanced AI tools like GPT-4 are trained on large amounts of data, text and images.
Lead researcher Dr. Andy Huang, an ophthalmology resident at Mount Sinai Eye and Ear Infirmary in New York, said the results show that AI can help treat eye diseases.
"It could serve as a reliable assistant for ophthalmologists by providing them with diagnostic support and potentially easing their workload, especially in complex cases or areas with high patient volume," Huang said.
"For patients, integrating AI into conventional ophthalmic practice could result in faster access to expert advice, along with more informed decision-making to guide their treatment," Huang added.
Final message In this study, an LLM chatbot had comparative and comprehensive diagnostic accuracy in glaucoma and retina versus trained ophthalmologists in both clinical questions and clinical cases. These findings support the possibility that artificial intelligence tools may play a critical role as both diagnostic and therapeutic adjuncts. |
SOURCE: New York Eye and Ear Infirmary of Mount Sinai, press release, February 22, 2024